
FÜGGELÉKEK
1. A TÖBBI ÍRÁS
Részben technikai okokból, a szükséges betűkészletek hiánya miatt, részben pedig az ismeretek hiánya miatt kellett most lemondanom számos írás ismertetéséről, de szeretném a későbbiekben ezeket is bemutatni. A következőkben ezek felsorolása következik.
Nyugati íráscsalád
KOPT. A görög ábécét használja kissé módosított betűformákkal és néhány kiegészítő betűvel. Az Egyiptomban ma is élő kopt keresztények vallási nyelvét írják vele.
SZÍR. Az arabra hasonlító, jobbról balra haladó írás, amellyel a szír nyelvet, a Közel-Keleten és Délkelet-Indiában élő ortodox keresztények liturgikus nyelvét írják; a nyelv sokak anyanyelve is. Példa:
THAANA. A Maldív-szigetek nyelvének, a divehinek írása. Az arab írás kissé átalakított változata.
Bráhmi íráscsalád
BALINÉZ. A Bali szigetén beszélt balinéz nyelv írása, a keleti bráhmi csoportba tartozik.
BATAK. A Szumátra szigetén beszélt batak dairi nyelv hagyományos írása; ma már inkább latin betűt használnak. A keleti bráhmi írások közé tartozik. Példa:

BUGINÉZ. A Celebesz szigetén beszélt buginéz és makaszar nyelv írása, a keleti bráhmi írások közé tartozik.
BURMAI. A burmai nyelvet és Burma számos kisebbségi nyelvet írják vele, a délkeleti bráhmi csoportba tartozik. Példa:

JÁVAI. A Jáva szigetén beszélt jávai nyelv írása, a keleti bráhmi csoportba tartozik.
KHMER. Kambodzsa hivatalos nyelvének, a khmernek írása, a délkeleti bráhmi csoportba tartozik. Példa:

LAO. Laosz nyelvének, a laónak írása, a délkeleti bráhmi csoportba tartozik. Példa:

SZINGALÉZ. A Srí Lankán beszélt szingaléz nyelv írása, amely a déli bráhmi csoportba tartozik. Példa:

TIBETI. A Tibetben beszélt tibeti nyelv írása, amely az északi bráhmi csoportba tartozik. Példa:

Íráscsaládba nem tartozó írások
CSEROKI. Európai hatásra kialakult szótagírás a cseroki és más indián nyelvek számára. Betűformái sokban emlékeztetnek a latin betűkre, de azokat nem eredeti jelentésük szerint használja. Dene nyelvű példa:
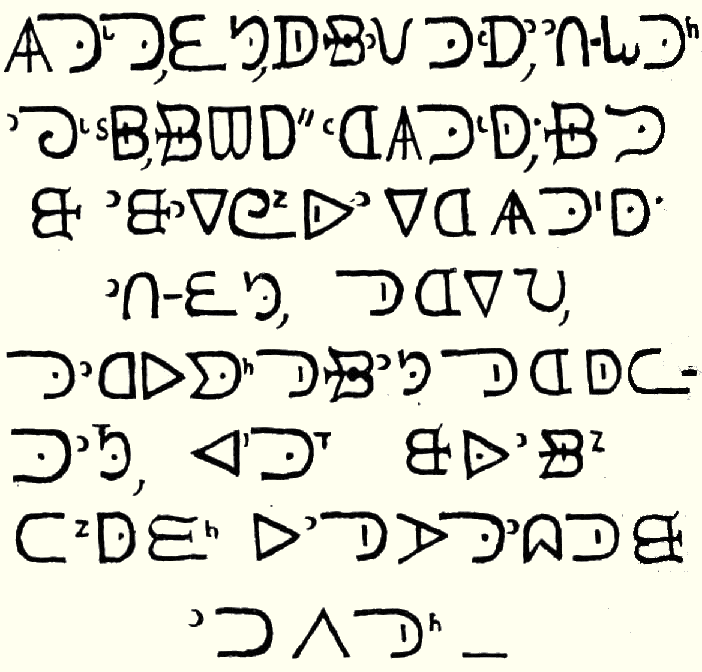
ETIÓP. Etiópia hivatalos nyelvének, az amharának írása, amelyet számos más nyelv is használ. Szótagírás, amelyben a mássalhangzókat jelölő alapbetűk logikus rendszer szerint változtatják alakjukat a csatolt magánhangzók szerint. Amhara nyelvű példa:

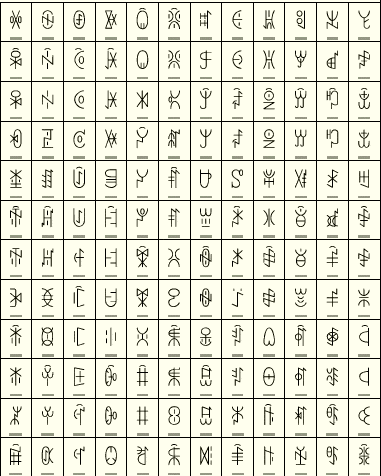
JI. A Kína délnyugati részén és a szomszéd országokban beszélt ji, más néven lolo vagy noszu nyelv írása. Szótagírás, amely földrajzi elhelyezkedése dacára semmilyen kapcsolatban nem áll a kínaival, nem is hasonlít rá. Nyolc-tízezer jelet használ. Az alábbi ábra a szótagjelek táblázatából mutat részletet.
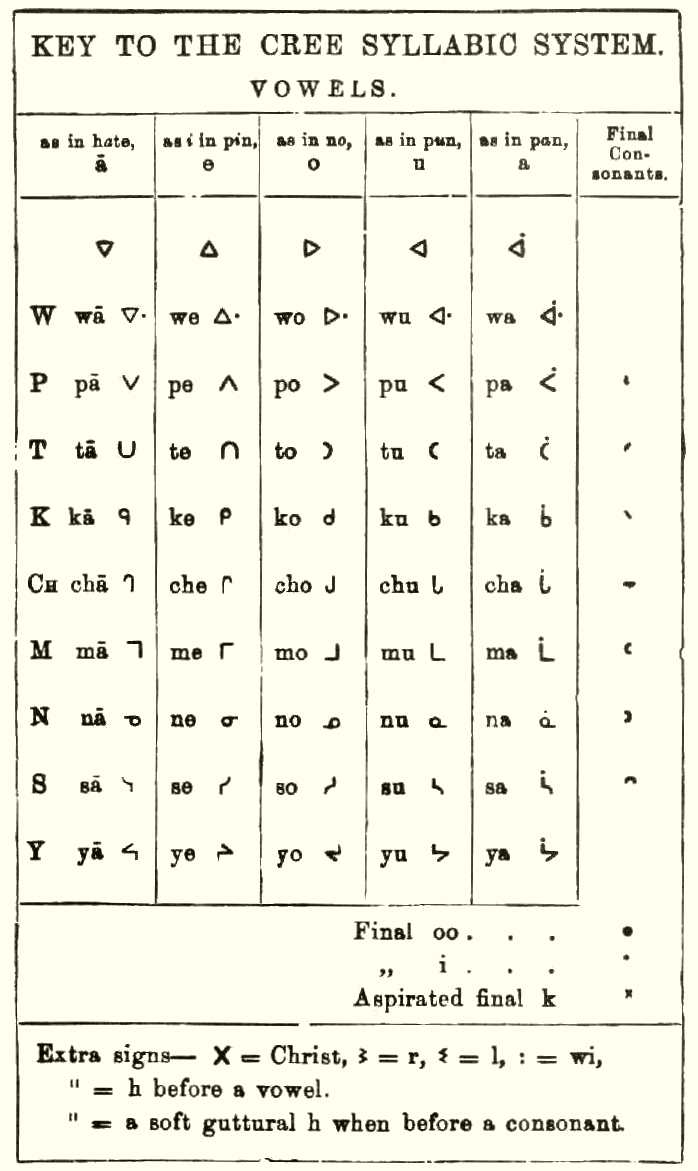
KANADAI SZÓTAGÍRÁS. Régebbi nevén krí írás: a krí nyelv számára hozták létre, de később átvette a csipeva, az odzsibve, az inuit, a szoltó és más nyelvek is. Szótagírás, a különböző magánhangzókat az alapbetű elforgatott és kiegészített változatai jelzik. A krí nyelvhez használt változat jeleit a felső ábra mutatja, az alsó inuit nyelvű példát közöl.

LISZU. A Thaiföld egyes vidékein és a környező országokban beszélt liszu nyelv írása, amelyet misszionáriusok hoztak létre a latin betűk felhasználásával. Példa:

MANDZSU. A mandzsu, mongol és kalmük nyelv írása, amely az arabhoz hasonlító folyóírás, de függőlegesen halad. Betűírás, amelyben a mássalhangzók alakot változtatnak a hozzájuk csatolt magánhangzóktól függően. Kalmük nyelvű példa:

Kihalt írások csak névsorolvasás szintjén: a germán rúnaírás (futhark), a kelta ogham rovásírás, az ómagyar rovásírás, a breton írás, az asszír ékírás, a krétai lineáris-A (mindmáig megfejtetlen) és lineáris-B írás, az egyiptomi hieroglifikus és démotikus írás, a fülöp-szigeteki tagalog írás (keleti bráhmi), a mikmak indián fogalomírás, a maja írás, a Húsvét-sziget rongo-rongo írása...
2. SPECIÁLIS ÍRÁSOK
Speciálisnak nevezhető minden olyan írás, amely nem abból a célból jött létre, hogy valamilyen beszélt nyelvet jegyezzenek le vele annak beszélői.
A Braille-írás
A Braille a vakok nemzetközi írása, amelyet nem tintával írnak, hanem a papírról kidomborodó pontok alakítják ki a betűket. Két változata van, hat- és nyolcpontos; mindkettőnél két oszlopban sorakoznak azok a helyek, ahol egy-egy pont kidomborodik vagy laposan marad. Akárcsak a latin ábécét, a Braille-t is hozzáigazították az egyes nyelvek hangkészletéhez, alapbetűi azonban változatlanok.
Az IPA ábécé
Neve az International Phonetic Alphabet rövidítése. A nyelvészek nemzetközi társasága által kidolgozott hangjelölési rendszer, amely latin és görög betűket használ. Célja bármely nyelv beszédhangjainak egységes megjelenítése tudományos célokból. Részletesen lásd a függelék Fonológia című fejezetében.
3. FONOLÓGIA
A fonológia a beszédhangokat mint a beszéd alapelemeit vizsgáló tudomány – nem azonos a fonetikával, amely a hangok történelmi fejlődését vizsgálja. Írásomban időnként fonológiai szakkifejezéseket használok egyes hangok pontos megnevezésére, ezek magyarázata következik ebben a fejezetben; ugyanakkor a beszédhangok tudományos leírására szolgáló IPA ábécé maga is egy írás, így munkám tárgykörébe tartozik.

Az IPA alapjeleinek első részét, a pulmonikus, azaz tüdőből kiáramló levegővel képzett mássalhangzókat a fenti ábra tartalmazza. Ezek mind úgy jönnek létre, hogy a toldalékcső – a légzőrendszernek a toroktól az ajkakig terjedő része – valamelyik pontján két hangképző szerv közeledik egymáshoz (részleges zár) vagy össze is ér, elzárva a levegő útját (teljes zár), miközben a tüdőből levegő áramlik ki. Azt a helyet, ahol a hangképző szervek zárnak, a képzés helyének nevezzük; a zár létrehozásának módját és az ahhoz kapcsolódó egyéb mozdulatokat a képzés módjának.
A vízszintes sorok a képzés helye, a függőleges oszlopok a képzés módja szerint sorolják be a hangokat. A kockák bal oldalán levő sötétkék betűk a zöngétlen, a jobb oldalán levő feketék a zöngés hangokat jelölik. A zöngések ugyanúgy képződnek, mint a zöngétlenek, de közben a hangszalagok rezegnek.
Az IPA-ban azok a betűk, amelyek nem tartalmaznak semmilyen „díszítést”, többségben a köznapi írásban érvényes hangértéküket képviselik: a táblázat első kockájában levő p-b tehát a közönséges p és b hang jele. Ezek segítségével könnyebben érthető a szakkifejezések jelentése: ejtsük ki többször egymás után a p, b és m hangokat, s érzékelhető lesz, mi az a bilabiális hang.
A sorok jelentése:
bilabiális: mindkét ajak használatával képzett hang;
labiodentális: ajakfoghang, az alsó ajak aktívan érintkezik a fogakkal;
dentális: a nyelv hegyével és peremeivel, valamint a felső fogakkal képzett hang;
alveoláris: a nyelv a felső fogsor mögötti kiemelkedéssel érintkezik;
retroflex: a nyelv hegye visszahajlik a fogmeder hátsó része a kemény szájpad eleje közti területhez (másik nevük: kakuminális hangok);
palatális: a kemény szájpadlásnál képzett hang;
veláris: a nyelv hátuljával és a lágy szájpadlással képzett hang;
uvuláris: a nyelvháttal és a nyelvcsappal (a lágy szájpadlás alsó részéről lelógó apró lebennyel) képzett hang;
faringális: torokhang, a garatban képzett hang;
glottális: a gégefőben, a hangszalagrés zárásával vagy szűkítésével képzett hang.
A feltüntetett sorrend tehát az ajkaktól a gégefőig fizikai elhelyezkedésük szerint osztályozza a hangokat.
Az oszlopok jelentése:
plozíva vagy explozíva: zárhang, teljes zár képződik, amely hirtelen felpattan;
nazális: a lágy szájpad leereszkedik, ezáltal a levegő az orrüregbe jut és ott rezonál;
pergőhang (trill, roll): az egyik hangképző szerv gyorsan, többször megérinti a másikat;
érintőhang (tap): egyetlen gyors érintkezéssel képzett hang;
frikatíva (réshang): két hangképző szerv olyan közel kerül egymáshoz, hogy a közöttük átáramló levegő hallható súrlódást okoz;
laterális frikatíva: réshang, amelynél a részleges zár egyik vagy mindkét oldalán a levegő képes kiáramlani;
approximáns: közelítő hang, amelynek képzésekor a hangképző szervek megközelítik egymást, zár vagy hallható súrlódás azonban nem jön létre;
laterális approximáns.
A magyar mássalhangzók helyét bemutatom a táblázatban. A p, b, m, f, v, t, d, n, r, z, l, j, k, g és h hangok saját betűjelükkel találhatók meg; az s betű (zöngétlen alveoláris frikatíva) az sz jele. A palatális plozívák közül a zöngés (c betű) a ty hang, a zöngétlen (fordított f) a gy hang. A zöngés palatális nazális (n betű baloldalt kampóval) az ny hang. A posztalveoláris frikatívák közül a zöngétlen (elnyújtott s betű) az s hang, a zöngés (lapos tetejű hármas) a zs hang.
Nagy számuk miatt a táblázatban nem szerepelnek az affrikáták, amelyek úgy keletkeznek, hogy egy plozívának megfelelő teljes zárat képezünk, majd ezt fokozatosan megszüntetjük, így átmenetileg frikatíva alakul ki. Zöngétlen alveoláris affrikáta keletkezik például, ha a t hangot (alveoláris plozíva) az sz hang (alveoláris frikatíva) követi azzal részben egybemosódva: ez a tsz, azaz a magyar c hang. Zöngés párja a dz. További affrikáták: alveoláris-posztalveoláris cs (t+s) és dzs (d+zs), psz, ksz (görög), pf (német), de ilyen a „medve” szó dv hangkapcsolata (zöngés alveoláris-labiodentális), s affrikáták a különböző hehezetes hangok is (kh, th, ph, gh, dh, bh). Az affrikátákat az IPA a két alkotóhang egymásutánjával jelöli, függetlenül attól, hogy azokat a nyelv egy hangnak tekinti-e vagy kettőnek. (Ez általában attól függ, hogy az affrikáta két elemét hol képzik. A c hang például két alveoláris részből áll, a hangképző szervek alig mozdulnak közben; a cs hangnál is csak egészen keveset mozdul hátra a nyelv a t elem és az s elem képzése között – ezért ezeket általában egy-egy hangnak tekintik a nyelvek, akkor is, ha több betűvel írják le. Jóval nagyobb mozdulat kell a német pf affrikátához, így könnyebb felismerni, hogy két részből áll.)
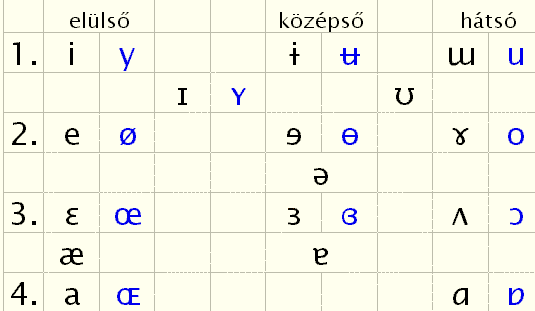
A fenti ábra a magánhangzók rendszerét mutatja be. A képzés helye szerint elülső, középső és hátsó, valamint közel elülső és közel hátulsó magánhangzók vannak; a képzés módja szerint pedig 1. zárt, 2. zárt-közép, 3. nyílt-közép, 4. nyílt, illetve közel zárt, középső és közel nyílt. Ezek többségének kerekítetlen (fekete) és kerekített (sötétkék) változata is van.
A „díszítetlen” betűk itt a „köznapi” magánhangzókat jelölik, amelyek közül három (i, o, u) a magyarban is megvan, az a és e viszont a nemzetközi változatú hang: nyílt kerekítetlen elülső, illetve zárt-közép kerekítetlen elülső magánhangzó. A magyar a hang a táblázat jobb alsó sarkában található kékkel: nyílt hátsó kerekített. (A nyelv enciklopédiájának magyar kiadása a nyílt-közép hátsó kerekített jelét használja, ez azonban az angol szótárakban is előfordul például a „not” szó fonetikus átírásában, és nem azonos a magyar a-val. Saját kutatásaim szerint a magyar a-t legjobban a mondott jel, a fordított „pocakos” a betű közelíti meg.) A magyar e pedig nyílt-közép elülső kerekítetlen. Az ö és ü hangoknak több változata is megtalálható a táblázatban, amelyek között a magyar nem tesz különbséget; így az ö ejthető zárt-közép vagy nyílt-közép elülső kerekítettként, az ü lehet zárt vagy közel zárt elülső kerekített.


A fenti ábrán a nem pulmonikus mássalhangzók jelei láthatók, mindenekelőtt a korábban már említett csettintő hangok. Ezek úgy jönnek létre, hogy 1. a nyelv hátsó részét a szájpadláshoz nyomjuk és a száj elülső részében is zárat hozunk létre – ezáltal egy üreg képződik a szánkban, amelynek nincs kapcsolata a kinti levegővel –, 2. a nyelvet kissé leeresztjük, ezáltal részleges vákuum keletkezik az üregben, 3. az üreget kapcsolatba hozzuk a kinti levegővel úgy, hogy kinyitjuk a szánkat vagy megszüntetjük a hátsó zárat, ezáltal a beáramló levegő csettintő hangot hoz létre.
Legalábbis így mondja a leírás, de én változatlanul nem tudom egyiket se kiejteni. Azaz egyet igen: az alveolárisat, amely a magyarban is megtalálható, csak nem használjuk szavak részeként: amikor rosszallóan cöcögünk, két alveoláris csettintőhangot ejtünk ki.
Csettintő hangok leginkább Dél-Afrikában használatosak, főként a koiszan nyelvcsaládban. Az ide tartozó !xu vagy kung-ekoka nyelv, amelyet Namíbiában és Angolában mindössze ötezer ember beszél, száznegyvenegy mássalhangzót használ, ebből negyvennyolc csettintő. Ezek között olyanok is akadnak, mint glottalizált zöngés laterális affrikált velarizált palatális, aminek elsajátítása becslésem szerint egy hétig tartana olyan embernek is, aki már boldogul a közönséges csettintőkkel.
Ami a zöngés implozívákat illeti, ezek olyan hangok, amelyeket befelé áramló glottális levegővel képeznek. Főleg amerikai és afrikai nyelvekben fordulnak elő nagy számban.
A nem pulmonikus mássalhangzók harmadik csoportját, az ejektívákat nem tüntettem fel a táblázatban, mert jelölésük egyszerűen egy aposztrófból (’) áll, amit a megfelelő zár- vagy réshang jele után írnak (például bilabiális: p’, alveoláris frikatíva: s’). Az ejektívák az implozívák fordítottjai, amennyiben kifelé áramló glottális levegővel keletkeznek.
Részletesebb magyarázattal nem szolgálhatok, mivelhogy természetesen ezeket sem tudom kiejteni.


A fenti ábra néhány további IPA-jelet mutat be. Köztük van a zöngés labioveláris approximáns, vagyis az angol w hang, valamint a lengyelnél már látott két alveolopalatális frikatíva, vagyis az „éles” s és zs.
Ezeken kívül az IPA számos ékezetet használ, amelyek például zöngétlenné vagy zöngéssé teszik a hangot, jobban vagy kevésbé kerekítetté, előretolt vagy hátrahúzott nyelvet írnak elő, lehelt, rekedtes, labializált, palatalizált, velarizált, faringalizált és még sokféle ejtést jelölnek, nem beszélve a zenei hangsúlyok jeleiről.
4. ÉKEZETTAN
Ilyen tudomány ugyan nem létezik, de azért érdemes némi külön figyelmet szentelni az eddig csak érintőlegesen említett ékezeteknek.
A magyar helyesírás szabályai következetesen ékezetnek nevezi a magyar á, é, ö, ü, ő, ű betűknél használt jeleket, de a mellékjel szót használja, amikor idegen nyelvek hasonló jeleiről tesz említést. Nyitva hagyja a kérdést, hogy például az é betű egy e-ből és egy ékezetből, avagy egy e-ből és egy mellékjelből áll-e vajon abban az esetben, ha egy francia névben fordul elő, mint például Gérard. Voltaképpen a kérdésnek nincs is értelme, mert a szabályzat semmilyen megkülönböztetést nem tesz a kettő között azon kívül, hogy ezzel a kevéssé demokratikus megkülönböztetéssel illeti őket.
Nevezzük tehát őket egységesen ékezetnek és nézzük meg, milyenfélék vannak ebből a latin írásrendszerben.
Ez az írásrendszer többek között abban különleges, hogy előszeretettel alkalmaz ékezeteket a nyelvek speciális hangjai számára. Mint azt egy korábbi fejezetben bemutattam, a különböző nyelvek hajlamosak más-más módon megoldani az alapábécében nem szereplő hangok jelölését: ugyanazt a hangot az egyik nyelv betűkapcsolattal, a másik ékezettel, a harmadik mindenféle kerülő úton (mint az angol enough szóban) jelöli. Más írásrendszerekben ez nem így van: a cirillnél inkább valamilyen módon áttervezik a meglevő betűket vagy kitalálnak teljesen újakat, az arabnál alul-felül különböző számú pontot alkalmaznak, a bráhmi írásokban új betűt vezetnek be. A latin írás azonban olyan sok nyelvet hódított meg és azok annyira különböznek egymástól mindenféle szempontból, hogy ennek hatása szükségszerűen tükröződik az írásrendszerben is.
Ékezetnek általában olyan jelet nevezünk, amely az alapábécé valamelyik betűjére illeszkedik; ennek három módja lehet:
1. a betű fölött;
2. a betű alatt;
3. a betű testén vagy belsejében.
Nem ékezet tehát a kis j betű pontja, mert ennek eltávolításával egy nemlétező betűt kapunk; s nem ékezet az y alsó nyúlványa sem, mert eltávolításával létező betűt kapunk ugyan, a v-t, de az y maga is része a huszonhat betűs alapábécének.
Ékezetnek ezenfelül csak olyasmit tekinthetünk, amit legalább egy létező latin betűs nyelv használ mindennapos írásában.


Hányféle ékezetet ismer a latin írásrendszer és mik azok? Erre a fenti ábra ad választ, amely bemutatja az Európában használatos latin ékezeteket: tizennyolcfélét, magyar és angol nevükkel együtt. Különböző betűkkel persze, hiszen nincs olyan betű az ábécében, amely létező kombinációkat adna az összes ékezettel.
Az ékezetek többsége felülre kerül, ezek között szinte minden egyszerű geometriai forma megtalálható. Egy részük görög eredetű, mások a meglevők módosításaival alakultak ki. A dupla vessző például német találmány, az umlaut „alternatív írásmódja” volt: a pont gyors kézírásban gyakran kis vonallá változik, s ezt egyes nyomtatott betűtípusok is utánozzák. A németben azonban a dupla vessző soha nem volt jelentésmegkülönböztető szerepű, ugyanolyan alakváltozat, mint a vessző helyett használt vízszintes vagy majdnem vízszintes vonal egyes betűtípusokban. Ékezeteket tehát úgy is lehet írni, mint más ékezeteket, ha azok nem fordulnak elő ugyanabban a nyelvben.
Néhány ékezet hajlamos speciálisan viselkedni. A hacsek a felnyúló szárú betűk (d, l, t) mellett aposztróffá változik a csehben és a szlovákban – máshol nem kapcsolódik felnyúló szárú betűkhöz –, s csak régies betűtípusokban jelenik meg a kis d, l, t fölött is V alakban. Az i betű pontja ékezetként viselkedik a törökben:
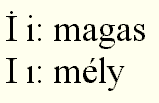
A ponttal ellátott i a magyarban is meglevő magas hangrendű hang, a pont nélküli az orosz jerinek megfelelő mély hangrendű. A török nyelvben tehát nem hiba, ha valaki a nagy I-re kiteszi a pontot. A lettben viszont a bal farok változtat alakot a g betű esetén, hogy a betű ne nyúljon túl mélyre:
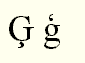
Az áthúzás a betű formájától függően lehet vízszintes vagy ferde, s egy esetben az eredeti betű formáját is megváltoztatja:



Párosítsuk össze a betűket az ékezetekkel s nézzük meg, milyen kombinációk fordulnak elő – a fenti táblázat nem lehet teljes, hisz számos nyelvről nincs információm, s napjainkban is rendszeresen készítenek latin írásrendszereket eddig más írást használó vagy írásbeliség nélküli nyelvekhez. A pirossal jelölt betűket csak nem latin betűs nyelvek átírásaihoz használják, némelyiket igen régóta és megszilárdult formában, ezért kerültek bele a táblázatba. Kiegészíthettem volna a táblázatot olyan ékezetekkel is, amiket kizárólag átírási céllal használnak – ilyenek a fordított vessző, a fordított csónak, az alsó karika, az aláhúzás, az alsó kalap, az alsó tilde, az alsó csónak, az alsó umlaut –, de akkor nagyon nagyra dagadt volna.
5. ÍRÁSOK SZÁMÍTÓGÉPEN
A ma létező írásrendszerek túlnyomó többsége jóval idősebb nemhogy a számítógépnél, de az írógépnél is. Amíg az emberek tollal írtak, az írás jelei bármilyenek lehettek, bármilyen sorrendbe lehetett őket állítani, az írásalkotók fantáziáját semmi sem korlátozta. Az írógép már próbára tette kissé a mérnökök ügyességét, nem kis feladat volt megtanítani neki a kínai írás sok ezer jelét vagy az arab betűk alakváltó szokásait. De megcsinálták, mert az egyetlen feladat, amit ehhez meg kellett oldani, az volt, hogy kiöntsék fémből a szükséges betűformákat és valahol elhelyezzék hozzáférhetően.
A számítógépnél ez nem elég. Ez a szerkezet nem arra szolgál, hogy a papírra nyomja egy betű képét és aztán elfelejtse, ez tárolja a szöveget és műveleteket végez vele, márpedig tárolni csak számokat képes. Ezért minden szöveget számokká kell alakítani, úgy persze, hogy aztán vissza lehessen változtatni olvasható szöveggé.
Ennek a műnek az illusztrációi képként tartalmazzák a bemutatni kívánt jeleket és szövegeket. Ahol a képeken O betű van, ott egy kör minden egyes pontjáról külön tárolja a gép, hogy az fekete, míg a körön kívüli és belüli pontokról azt, hogy fehérek. Ez a módszer tehát meglehetősen helyigényes, ráadásul nehéz megváltoztatni: ha be szeretnék illeszteni egy szót valamelyik példaszövegembe, az egész képet át kellene rendezni.
Amikor az első számítógépek megjelentek, ezek a problémák föl sem merültek, mert ilyen képeket egyáltalán tárolni és kirajzolni sem lehetett, nemhogy megváltoztatni – nem volt elég hozzá a memória. Az akkori tervezők nem is álmodtak arról, hogy O betűket finom rajzolatú körökből állítsanak elő, ehelyett azt az elvet alkalmazták, hogy a betű kap egy számkódot, jelen esetben a 79-est, és minden szöveg minden O betűjét ugyanazzal a 79-cel fogják kódolni. És valahol lesz a gépben egy táblázat, ami közli, hogy amikor a szöveget megjeleníti, milyen rajzot kell társítania az egyes kódokhoz.
A számítógépek mindmáig kettes számrendszerben számolnak és nyolcasával csoportosítják a számjegyeket: minden nyolc darab kettes számrendszerbeli számjegyet egy egységként kezelnek, aminek a neve byte. Kézenfekvő volt, hogy minden byte egy jelet kódoljon; ha tehát három byte áll egymás után és értékük rendre 79, 80, 81, akkor ez úgy olvasandó: OPQ. Egy byte 256-féle értéket vehet fel, hiszen ennyi kettő a nyolcadik hatványon. Mivel a számítógépeket az USA-ban találták fel és sokáig magától értetődőnek tekintették, hogy aki számítógépet használ, az tud angolul és a gépet matematikai célokra használja, nem tamil szövegek rögzítésére, ez a 256 bőségesen elegendő volt az ékezeteket nem ismerő angol nyelv összes jelének kódolására – sőt csak a felét használták fel, a 0-tól 127-ig terjedő kódokat, amikből az első harminckettőt különböző vezérlési célokra tartották fenn, a többi képezte az ASCII szabványhoz tartozó megjeleníthető jeleket, amint az alábbi ábra mutatja. A kék számok a kódok, baloldalt az első (két) jegy áll, felül az utolsó; sötét foltok jelölik azokat a kódokat, amiket nem definiáltak vagy vezérlőjelet jelentenek, a 32-es kódszámnál olvasható „sz” pedig a szóköz jele, 32 a szóköz kódja.

A kódtartomány második felét, a 128-tól 255-ig terjedő kódokat soha nem definiálták egységesen, erre számtalan többé-kevésbé elterjedt szabvány alakult ki. Így például a PC gépeken futó DOS operációs rendszer sokáig az alábbi ábrán látható táblázatot használta, amit 437-es kódtáblának hívnak – misztikus módon, merthogy 436-os vagy 435-ös soha nem létezett.
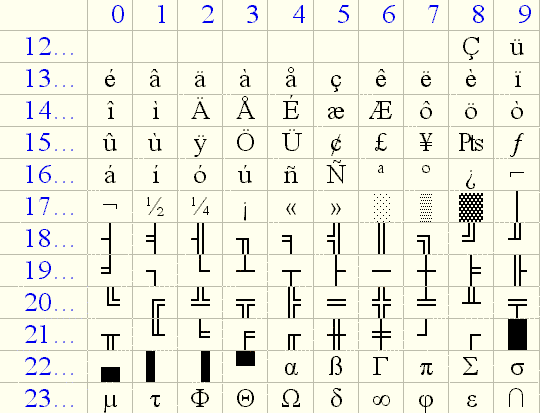

Ma is ismeri ezt a táblázatot minden PC. Az ékezetes betűk sora nagyjából fedi a német, francia, olasz, svéd és spanyol igényeket, ám a készítő megfeledkezett arról, hogy az ae ligatúra a ma élő nyelvek közül csak a dánban és a norvégban használatos, de ezek nem írhatók le a jelkészlettel, mert nincs áthúzott o. A jelkészletet összeállító IBM cég a portugálról, az izlandiról, a walesiről és a törökről is megfeledkezett, ami pedig a kelet-európai nyelveket illeti, azokat akkoriban a vasfüggöny mögött beszélték és a jólnevelt amerikai számítástechnikusnak fogalma sem volt róla, milyen betűk szükségesek hozzájuk. Nem is kellett tudnia, hiszen ezekbe az országokba tilos volt számítógépeket exportálni. Ennél sokkal fontosabb volt, hogy a géppel lehessen jópofa kereteket, vonalas rajzokat csinálni – másféle rajzról még egy darabig nem is esett szó –, és egyszerűbb matematikai képletekkel is boldoguljon.
A politikai szűklátókörűség technikai problémákat szült, amikor a vasfüggöny elolvadt és ezek a gépek megjelentek Kelet-Európában is. A szoftvercégektől semmilyen segítséget nem remélhető kelet-európai számítástechnikusok saját szakállukra magyarosították a gépeket. Mindenki máshogyan, mindenki más kódszámot választott a hiányzó betűknek, amihez persze ki kellett dobni a táblázat illető helyein álló eredeti jeleket, hiszen egy kód csak egyféle betűt jelölhet.
Magyarországon is többféle változat keringett egy ideig. A három legelterjedtebb rendszerben használt kódszámokat mutatja ez a táblázat:
|
betű |
CWI–1 |
CWI–2 |
SZKI |
|
ő |
147 |
147 |
219 |
|
ű |
150 |
150 |
220 |
|
Á |
143 |
143 |
199 |
|
Í |
140 |
141 |
205 |
|
Ó |
149 |
149 |
209 |
|
Ú |
151 |
151 |
214 |
|
Ő |
167 |
139 |
221 |
|
Ű |
152 |
152 |
222 |
Végül a CWI–2-es vált kváziszabvánnyá hazánkban. (Jellemző az akkori viszonyokra, hogy miért. A legfőbb szempont az volt, hogy ezzel lehet legjobban olvasni a magyar szöveget olyan gépen, amely nincsen magyarosítva, így a megváltoztatott betűk helyett a 437-es tábla eredeti jeleit mutatja. A következő ábra mutat írásmintát magyar ékezetes szövegből a háromféle szabvány szerint kódolva és a 437-es kódtáblával ábrázolva.

A kilencvenes évek elején a legtöbb magyar felhasználó képernyőjén, sőt nyomtatóján is így jelentek meg a magyar szövegek, s ma is így jelennének meg egy minden különösebb segédprogram nélkül, közönséges DOS-szal, magyarosítatlanul elindított PC-n, hiszen továbbra is a 437-est építik beléjük.)
Ekkor azonban a Microsoft, meghallva az idők szavát, elkezdett kódtáblázatokat kidolgozni az eddig lefedetlen „régiók” számára, nemigen látva át, hogy a földrajzi közelségből még nem szükségszerűen következnek a szoros kulturális kapcsolatok. Így kerültek a magyar betűk a környező országok nyelveinek betűivel egy táblázatba, ez lett a 852-es kelet-európai kódtábla:


amely meglehetős népszerűségre tett szert annak ellenére, hogy magyar szövegben sokkal gyakrabban kell francia neveket, kifejezéseket idézni, mint lengyeleket vagy szlovákokat, márpedig a francia betűk ebben a jelkészletben nem szerepelnek, így hozzáférhetetlenné váltak. A DOS – helyesebben az általa használt képernyőüzemmód – tulajdonsága, hogy egyszerre csak egy jelkészlet használható, mert ha másikra kapcsolunk, az egész képernyő azonnal átvált egységesen.
A kódszámokból persze csak akkor lesz látható betű, ha van egy táblázat a gépben, amely megmondja, milyen a betűk alakja. Eleinte nyolcszor nyolcas, később nyolcszor tizenhatos négyzetrácsban rajzolták meg a jeleket; erre a következő ábra mutat példát, amely egy nyolcszor nyolcas mátrixban megrajzolt kis f betűt ábrázol.
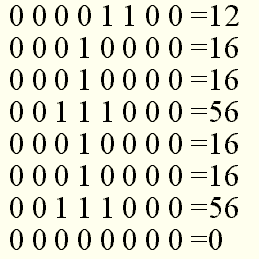
Minden sor egy byte-nak felel meg, ahol az 1-es helyiértékű számjegyek jelentik a betűt, a 0-sak a hátteret. A kettes számrendszerbeli számok tízes megfelelője a táblázat jobb oldalán látható. Ez a tárolási módszer igen gyors és kényelmes, viszont meglehetősen durva rajzolatot ad; a nyolcszor tizenhatos sem sokkal finomabbat.
A 852-esnek azonban nemigen sikerült kiszorítania a CWI-2-est (és a többi ország nemzeti szabványát), mert időközben a DOS elavult, s a kérdés áttevődött a Windows rendszerbe.
Itt megint másképpen helyezték el a jeleket a rendelkezésre álló 128 kódhelyen. A Windows mai nyugat-európai kódtáblája:


Windows alatt egy-két dolog másképpen nézett ki. Az eddig használt karakteres képernyőüzemmód helyett most már grafikus módban dolgozott a gép, így egyrészt finomabb rajzolatúak lehettek a jelek, másrészt megfelelő programmal arra is volt mód, hogy több jelkészlet jeleit vegyítsék: a program kirajzolt egy jelet, ami a továbbiakban puszta képinformációként viselkedett, így a következő jel bármilyen más jelkészletből származhatott, ez a már kirajzolt jelet nem érintette. Ha átrendezést kellett végrehajtani a szövegen, a program az összes látható jelet újrarajzolta. Ekkorra már volt elegendő memória a gépekben és elég gyorsak is voltak hozzá, hogy ezt elvégezzék.
Egyvalami azonban nem változott ekkor sem: a kódolás módja. Továbbra is minden jelet egy byte kódolt, továbbra is 256-féle jelet lehetett tárolni egy jelkészletben, sőt még ennyit sem, mert a 0-tól 31-ig terjedő számokat a Windows lefoglalta vezérlési célokra.
A kóddzsungel tovább növekedett. Ekkorra már seregnyi DOS-os kódtábla volt használatban, mint például a 850-es többnyelvű, amely a 437-esben található ékezetes betűket megtoldotta a dán, norvég, portugál és izlandi betűkkel; a 855-ös cirill, amely az orosz mellett a szerb, macedón, ukrán betűket is tartalmazta; a 857-es török; a 869-es újgörög és több más. Most megjelentek a windowsos kódtáblák is, amelyek persze még véletlenül sem egyeztek meg az azonos nyelvcsoportokhoz készített DOS-os táblákkal. A fentebb bemutatott nyugat-európai kódtábla az 1252-es sorszámot viselte, de volt 1250-es kelet-európai (ugyanazokkal a nyelvekkel, mint a 852-es), 1251-es cirill, 1253-as görög, 1254-es török és 1257-es balti (lett, litván, észt, lengyel, finn, svéd, dán, norvég). Nem beszélve persze a rengeteg házi gyártmányú jelkészletről, amik semmilyen szabványt nem követtek. A cirill betűket például az összes szabvány a tábla második felébe helyezte el, de készültek olyan cirill jelkészletek, amelyek a közönséges latin betűket helyettesítették be velük, például a Q helyére került a cirill i, az A helyére a ja – így ugyanis nem volt szükség külön billentyűkezelő programra, a felhasználó csak lenyomta a billentyűket és megjelentek a betűk abban az elrendezésben, ahogy az orosz írógépeken szerepel. Éppen csak az ilyen kódrendszerek semmivel nem voltak kompatibilisek.
A dzsungelben rendet kellett teremteni. Ennek érdekében hozták létre a Unicode-ot.
A Unicode abból a felismerésből indul ki, hogy 256 jel márpedig nem elég. Egy byte-on nem lehet kódolni a világon használt töméntelen jelet, még akkor se lehetne, ha a kínai írás nem létezne. De létezik, és szükség van arra, hogy ezeket egy dokumentumon belül, kényelmesen lehessen használni más írások, akár az arab vagy a grúz jeleivel. Enélkül nincsenek szótárak, többnyelvű kiadványok, nincs nemzetközi szövegfeldolgozás.
Két byte azonban már bőven elég. Ez tizenhat bitet jelent, kettő a tizenhatodikon pedig 65 536. Ennyiféle jellel már minden írás kódolható, néhány tízezret nyugodtan oda lehet adni a kínainak, még mindig marad elég. Sőt mivel egy tartományt definiáltak a „pótlásoknak”, ami azt jelenti, hogy az itt található kódokat párba állítva kell értelmezni egy matematikai formula szerint, a kódolható jelek száma millión felül van.
A Unicode rendszer kisebb-nagyobb tartományokra osztja a hatalmas jelkészletet, amelyek tizenhatos számrendszerben kerek számoknál kezdődnek; a kezdőpontok sorszámai állnak a következő táblázat első oszlopában. A második oszlop azt mutatja (most már tízes számrendszerben), hogy hány jelet definiáltak a tartományban.
|
0000 |
128 |
normál ASCII |
|
0080 |
128 |
latin–1 |
|
0100 |
128 |
latin bővítés A |
|
0180 |
194 |
latin bővítés B |
|
0250 |
94 |
IPA-bővítések |
|
02B0 |
63 |
fonetikai módosítójelek |
|
0300 |
82 |
kombinálható ékezetek |
|
0370 |
112 |
görög és kopt |
|
0400 |
238 |
cirill |
|
0530 |
86 |
örmény |
|
0590 |
84 |
héber |
|
0600 |
206 |
arab |
|
0700 |
71 |
szír |
|
0780 |
49 |
thaana |
|
0900 |
104 |
dévanagári |
|
0980 |
75 |
bengáli |
|
0A00 |
75 |
gurmukhi |
|
0A80 |
78 |
gudzsaráti |
|
0B00 |
79 |
orijá |
|
0B80 |
61 |
tamil |
|
0C00 |
80 |
telugu |
|
0C80 |
80 |
kannada |
|
0D00 |
78 |
malajalám |
|
0D80 |
79 |
szingaléz |
|
0E00 |
87 |
thai |
|
0E80 |
65 |
lao |
|
0F00 |
193 |
tibeti |
|
1000 |
77 |
burmai |
|
10A0 |
78 |
grúz |
|
1100 |
240 |
koreai dzsamó |
|
1200 |
345 |
etióp |
|
13A0 |
85 |
cseroki |
|
1400 |
629 |
kanadai szótagírás |
|
1680 |
29 |
ogham |
|
16A0 |
81 |
futhark |
|
1780 |
104 |
khmer |
|
1800 |
155 |
mongol |
|
1E00 |
246 |
további latin bővítés |
|
1F00 |
233 |
görög bővítés |
|
2000 |
83 |
általános írásjelek |
|
2070 |
28 |
felső és alsó indexek |
|
20A0 |
16 |
pénznemjelek |
|
20D0 |
20 |
kombinálható szimbólumok |
|
2100 |
59 |
betűszerű jelek |
|
2150 |
49 |
számformák |
|
2190 |
100 |
nyilak |
|
2200 |
242 |
matematikai jelek |
|
2300 |
153 |
egyéb technikai jelek |
|
2400 |
39 |
vezérlőjelek képei |
|
2440 |
11 |
optikai jelfelismerési jelek |
|
2460 |
139 |
bekarikázott alfanumerikus |
|
2500 |
128 |
vonalgrafikus jelek |
|
2580 |
22 |
dobozelemek |
|
25A0 |
84 |
geometrikai alakzatok |
|
2600 |
109 |
egyéb szimbólumok |
|
2700 |
144 |
dingbatok |
|
2800 |
256 |
Braille-pontminták |
|
2E80 |
115 |
CJK-gyökök bővítése |
|
2F00 |
214 |
kanghszi gyökök |
|
2FF0 |
12 |
ideografikus leírójelek |
|
3000 |
61 |
CJK-szimbólumok |
|
3040 |
90 |
hiragana |
|
30A0 |
94 |
katakana |
|
3100 |
40 |
bopomofo |
|
3130 |
94 |
hangul-kompatibilitási dzsamó |
|
3190 |
16 |
kanbun |
|
31A0 |
24 |
bővített bopomofo |
|
3200 |
202 |
bekarikázott CJK-jelek |
|
3300 |
249 |
CJK-kompatibilitási |
|
3400 |
6 710 |
CJK-ideogrammák, A bővítés |
|
4E00 |
21 046 |
CJK egyesített ideogrammák |
|
A000 |
1 164 |
ji szótagok |
|
A490 |
50 |
ji gyökök |
|
AC00 |
11 171 |
hangul szótagok |
|
D800 |
0 |
pótlások (D800–DFFF) |
|
E000 |
0 |
magánterület (E000–F8FF) |
|
F900 |
301 |
CJK-kompatilitási ideogrammák |
|
FB00 |
58 |
alfabetikus prezentáció |
|
FB50 |
594 |
arab prezentáció A |
|
FE20 |
4 |
kombinációs féljelek |
|
FE30 |
28 |
CJK-kompatibilitási formák |
|
FE50 |
26 |
kis alakváltozatok |
|
FE70 |
140 |
arab prezentáció B |
|
FF00 |
208 |
fél és teljes szélességű formák |
|
FFF0 |
5 |
speciális jelek |
|
10300 |
35 |
óitáliai |
|
10330 |
27 |
gót |
|
10400 |
76 |
deseret |
|
1D000 |
246 |
bizánci kottajelek |
|
1D100 |
219 |
kottajelek |
|
1D400 |
991 |
matematikai alfanumerikus jelek |
|
20000 |
42 711 |
CJK-ideogrammák, B bővítés |
|
2F800 |
542 |
CJK-kompatibilis bővítés |
|
E0000 |
97 |
címkék |
Eddig tehát 94 441 jelet definiáltak a Unicode-ban (a 3.1-es változat szerint). Természetesen ez csak egy írott szabvány, nem program és nem jelkészlet; a programozók feladata, hogy ebből valóságot hozzanak létre, a gépeket megtanítva a Unicode kezelésére. Ez jelenleg is folyik, már vannak több Unicode-tartományt átfogó egyesített jelkészletek, de egyelőre nem láttam olyat, amely minden definiált tartományt ismert volna. A jelkészletek mellé kellenek programok is – eddig még nem készült olyan szövegszerkesztő, amely egyszerre tudta volna például az arabot és a kínait kezelni. Ez igencsak nehéz feladat. E könyv készítése közben például a kínai jeleket kínai szövegszerkesztővel értem el, arab viszont nem lévén kéznél, szövegmintáimat visszafelé írva kellett előállítanom úgy, hogy kiemelgettem a jeleket a táblázatból és egymás mögé sorakoztattam.
FELHASZNÁLT IRODALOM
A bemutatott írások jelentős részét nem vagy csak felületesen ismertem mindaddig, amíg e könyv számára tanulmányozni kezdtem őket. Ebben nagy segítségemre volt a The Unicode Standard Version 3.0 című könyv, amelyet a Unicode konzorcium adott ki és a www.unicode.org címen található meg.
A bráhmi íráscsalád, egyszersmind Ázsia legtöbb írásának átfogó képét adja Eden Golshani Scripts of All of Asia című összeállítása (http://www.geocities.com/Athens/Academy/9594).
Több hangtani kérdést segített tisztázni Peter Ladefoged An introduction to the sounds of languages című műve (http://hctv.humnet.ucla.edu/departments/linguistics).
Példaszövegeim forrása a Convent of Pater Noster című gyűjtemény (http://www.christusrex.org/www1).
A kínai írásban való eligazodásban nélkülözhetetlen volt Rick Harbaugh Zhongwen című nagyszótára (http://www.zhongwen.com).
A fonológiai szakkifejezések magyarázatát David Crystal A nyelv enciklopédiája című művéből vettem át (Osiris, Budapest, 1998; ISBN 963 379 211 8).
Egy helyen említem A magyar helyesírás szabályai című kiadványt (tizenegyedik kiadás, harmadik lenyomat; Akadémiai Kiadó, Budapest, 1986; ISBN 963 05 4406 7) (http://mek.oszk.hu/01500/01547).
 |
 |